Huh, tule seveda pljuvam v lastno skledo. Vendar menim, da akademska higiena to zahteva. Douglas Campbell (zelo aktiven tviteraš, sicer pa doktorat na odlični UC Davis in profesor na AP New Economic School) je napisal, kako sta s kolegico replicirala študijo Blooma, Drace in van Reenena (BDvR) o supervelikem učinku kitajske konkurence na povečano inovativnost evropskih podjetij. BDvR so ugotovili, da so evropska podjetja v panogah z večjo kitajsko konkurenco odgovorna kar za 30% povečanje inovativnosti in produktivnosti. Ta rezultat je v nasprotju z denimo študijo Autorja in kolegov (2017) “Foreign Competition and Domestic Innovation: Evidence from U.S. Patents“, ki so pokazali prav nasprotno za ZDA. Študija BDvR se je zato zmeraj zdela nekoliko sumljiva, vendar pa – ker je John van Reenen velika zvezda v ekonomiji (dobitnik nagrade za najboljšega evropskega ekonomista izpod 45, iz London School of Economics je presedlal na še bolj prestižni MIT) – se nihče ni lotil replikacije njihovih rezultatov.
Campbell & Mau sta seveda odkrila velike napake v empirični analizi BDvR in ko napake odpravita, super rezultati BDvR študije izginejo, predznak koeficienta se celo obrne in je statistično značilen. Podobno se je zgodilo, ko so Herndon, Ash in Pollin (HAP, 2013) poskušali replicirati še bolj razvpito študijo Reinhartove in Rogoffa o magični meji zadolženosti države pri 90% BDP, ko rast BDP postane negativna. Ekonomisti IMF so kasneje pokazali, da ni nobene takšne magične meje zadolženosti.
Nauk te zgodbe je seveda, da je nekaj narobe z recenzijami znanstvenih študij v ekonomiji in da bi morali vse rezultate neodvisno preveriti oziroma omogočiti replikacijo rezultatov s tem, da bi avtorji morali dati na voljo tako podatke kot ekonometrično kodo. To bi morala biti norma, predpogoj z aobjavo.
Je pa še en nauk, ki ga daje Campbell vsem ekonomistom, ki želijo objaviti v top-5 znanstveni reviji (ključen pa je pogoj št. 2!):
1. Adopt a very popular thesis — free trade magically induces innovation! 2. Be a well-connected “star”. 3. Feel free to “shoot a man on 5th avenue” in your analysis, you’ll be accepted if 1 & 2
In our paper, we find several coding errors which overturn a seminal paper in the “Chinese competition caused a huge increase in innovation” lit by Bloom et al (BDvR). From the beginning, I knew the BDvR paper had problems. Why? nbloom.people.stanford.edu/sites/g/files/…
Well, first I should say that I am actually somewhat empathetic about the coding errors, common in published papers–a reason we need replication. Any empirical researcher will make mistakes on occasion. But, there is a lot to chew on in this case besides the coding errors.
First, intuitively, the idea that Chinese competition directly led to up to 50% of the increase in patenting, computer purchases, and TFP growth in Europe from roughly 1996-2005 seemed unlikely. This from a relatively small increase in trade concentrated in a few sectors?
Second, BDvR’s identification strategy is a diff-in-diff, a comparison of firms in sectors that compete with China before and after China joined the WTO. Yet, the authors didn’t plot pre-treatment trends. Moreover, they didn’t plot any relevant data. Red flags everywhere.
Thus, one of the first things we did was merely plot the pre- and post-treatment trends for patents. Here’s what they look like, for the China-competing group (got quotas) vs. the No-quota (non-competing) group. Not compelling. 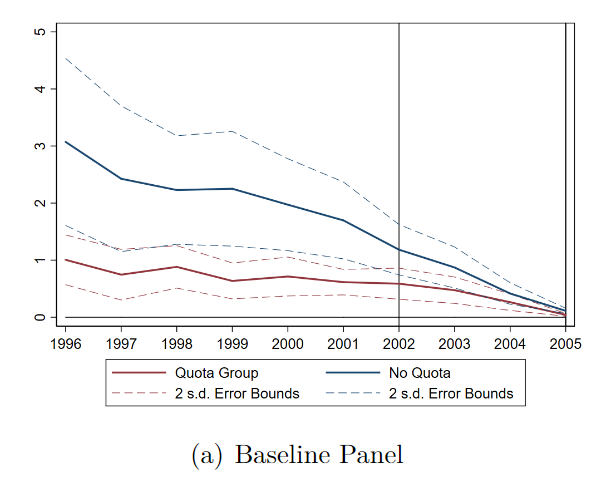
Note that there seems to be differential trends pre-treatment. Patents in the “No quota” (non-china competing) group seemed to be falling before China joined the WTO. Secondly, patents in both groups are just falling to zero. This is not mentioned in the paper.
Given the above graph, how/why did BDvR find any effects? Well, another thing that bothered me on my initial read is that the authors switch between data sets for each robustness check. The initial table contains no sectoral FEs. (Had they included, their results vanish.)
Thus, when BDvR include firm FEs, they switch to using a longer, different panel data set. When we plot the pre-treatment trends of that one, we get a different picture, but still with extreme tapering. We noted, even here, patents in both groups fell the same % from 2000 to 2005 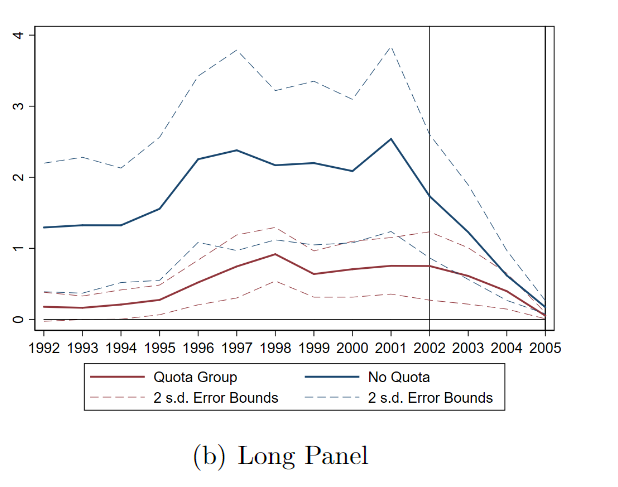
BDvR found a positive effect only b/c they normalize patents by adding one and taking logs. This transformation induces an obvious bias that will be larger for small numbers. The China-competing sectors had fewer patents to begin with, ergo a systematic larger bias. 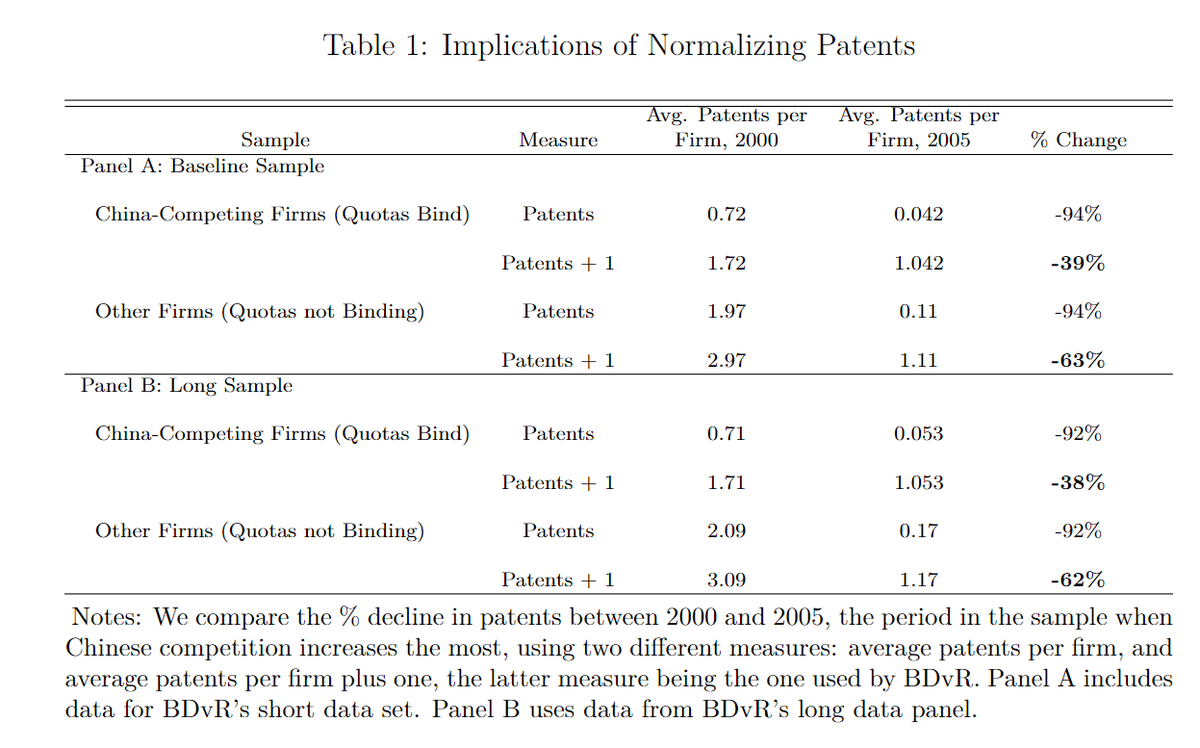
There was one regression in BDvR immune to this. The formulation using a negative binomial regression. However, we noticed that they continued to add one (inexplicably), and also included different FEs from what they reported. Fixing these errors (4), the results flip 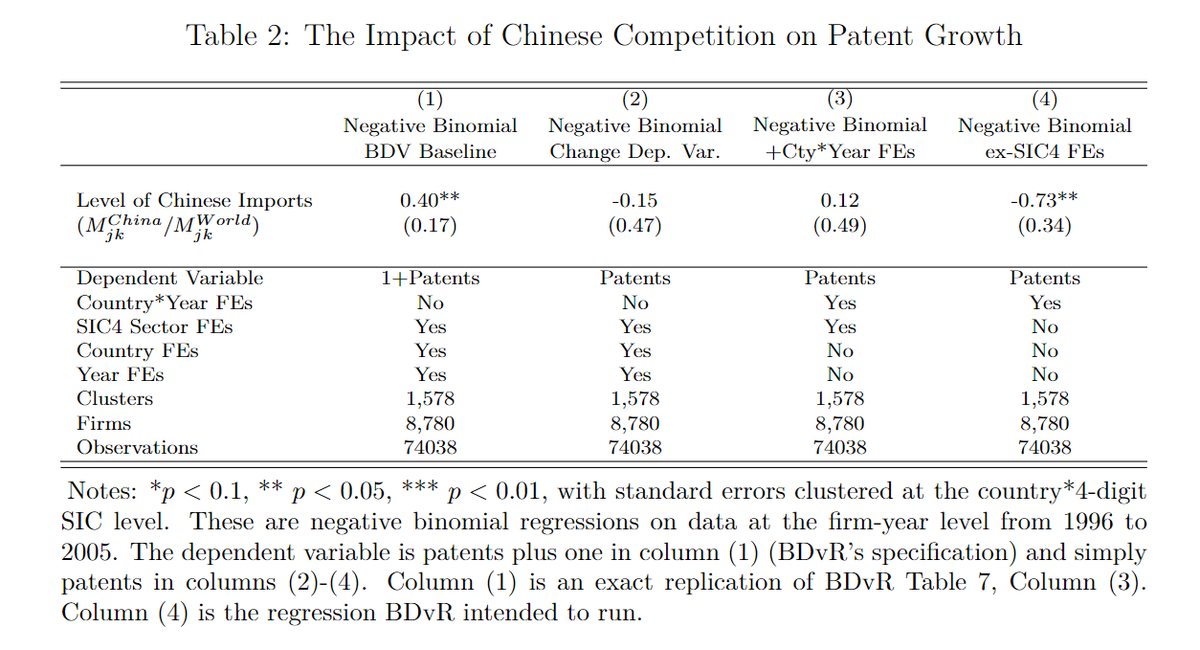
Note that, in these regressions, there is no identification, and no controls for trends, so these are just correlation in any case, with no compelling reason to attach a causal explanation.
The final version was slimmed down, but we had found issues elsewhere in their paper (the IT & TFP parts too). In the long patent panel, we found no correlation between Chinese comp. and patent growth to begin with, with or without their firm FEs.
Running a number of different specifications, altering the FEs and measure of Chinese competition used, we found that most variations the authors could have run would have been insignificant aside from the ones they reported. 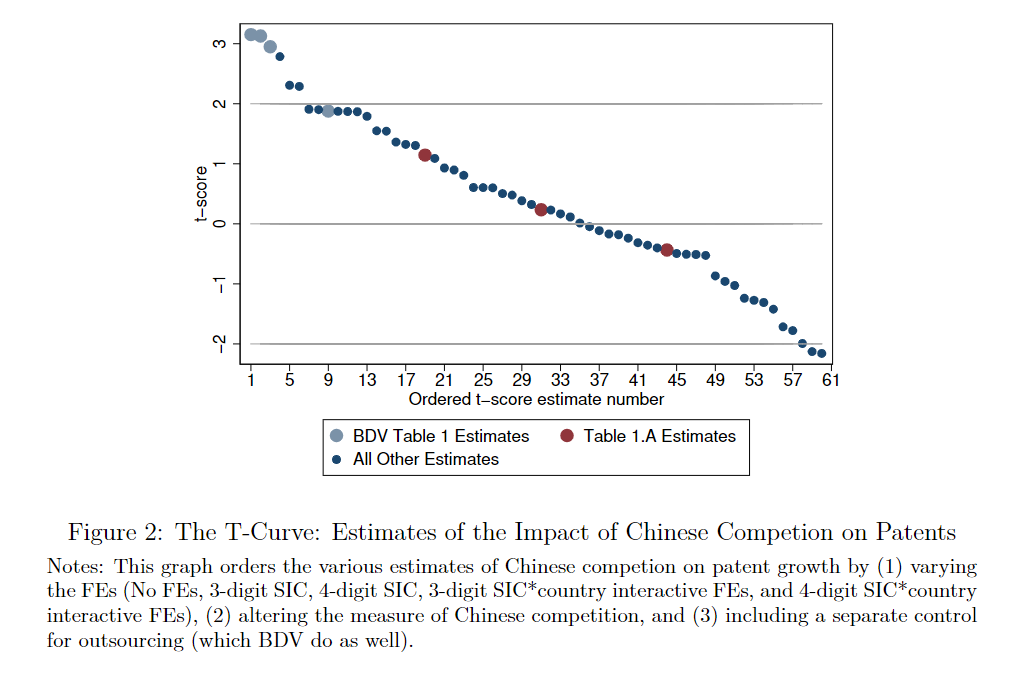 We also found the authors censored some of their data (log changes in patents). I’m not sure if they reported that they did this, but they did not report that if they uncensor, some of their results become insignificant.
We also found the authors censored some of their data (log changes in patents). I’m not sure if they reported that they did this, but they did not report that if they uncensor, some of their results become insignificant. 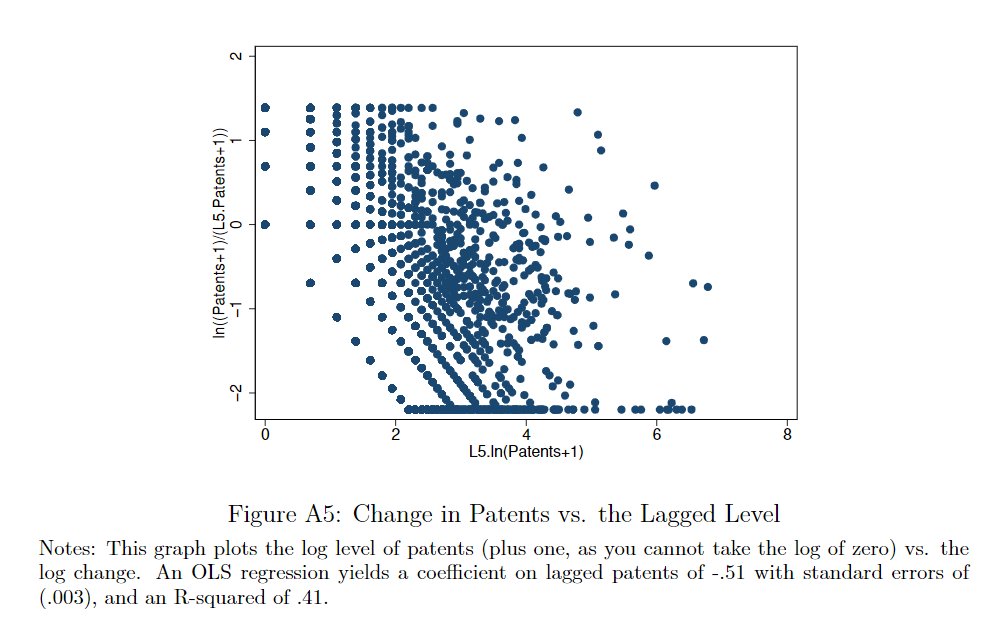
Overall, I think these (censoring, transforming vars, switching data sets) are helpful tricks to use for RAs or young scholars who coded up their data set, and can’t get their magical significance stars. Grad students at top programs likely already get trained to do these things.
Also, in defense of the authors, I don’t think there is anything unusual about this paper. This is how most empirical “research” is done in academic economics at the highest levels. While pointing it out is basically forbidden, it’s an open secret.
It’s very difficult to publish in a top 5. But, this case shows the way. 1. Adopt a very popular thesis — free trade magically induces innovation! 2. Be a well-connected “star”. 3. Feel free to “shoot a man on 5th avenue” in your analysis, you’ll be accepted if 1 & 2.
