Chris Giles iz Financial Timesa si je vzel čas in naredil hvalevredno analizo podatkov, ki jih Thomas Piketty uporablja v svojem presenetljivem bestsellerju “Capital in the Twenty-First Century“. Piketty je vse podatke in izračune dal na spletno stran knjige, da bi jih podvrgel kritični analizi kolegov in z namenom, da bi izboljšali obstoječe serije podatkov o porazdelitvi bogastva in dohodkov po državah.
Giles je po analizi podatkov zapisal, da je Piketty naredil precej napak pri analizi podatkov, da ima ponekod napake v izračunih, drugje pa se sklicuje na napačen vir. Giles te napake primerja z napakami Reinharove in Rogoffa, ki so jih odkrili lani. Toda po lastni analizi alternativnih podatkov je Giles prišel do zelo podobnih rezultatov kot Piketty (razen za Evropo, kjer ni zaznal bistvenega povečanja neenakosti po letu 1970).
Spodaj z namenom transparentnosti na kratko povzemam glavne ugotovitve Gilesa, odgovor Pikettyja, neodvisen povzetek obtožb s strani Justina Wolfersa ter kritiko Gilesa s strani Paula Krugmana, oboje v New York Timesu.
Piketty findings undercut by errors – Chris Giles, Financial Times
The data underpinning Professor Piketty’s 577-page tome, which has dominated best-seller lists in recent weeks, contain a series of errors that skew his findings. The FT found mistakes and unexplained entries in his spreadsheets, similar to those which last year undermined the work on public debt and growth of Carmen Reinhart and Kenneth Rogoff.
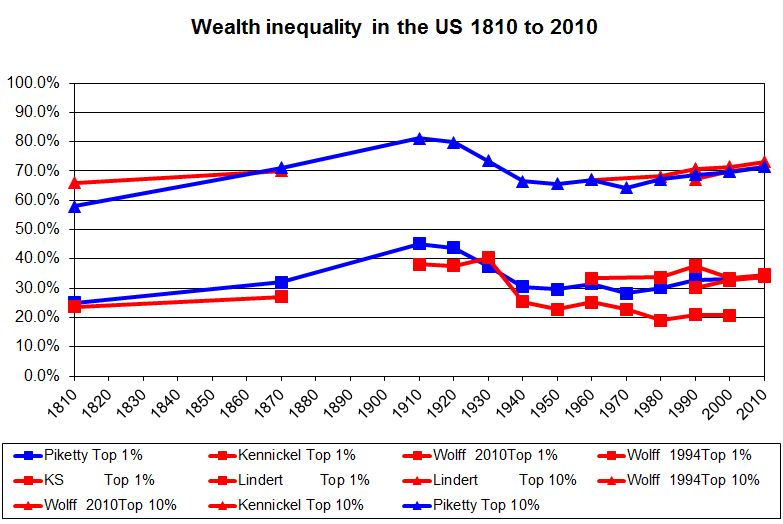
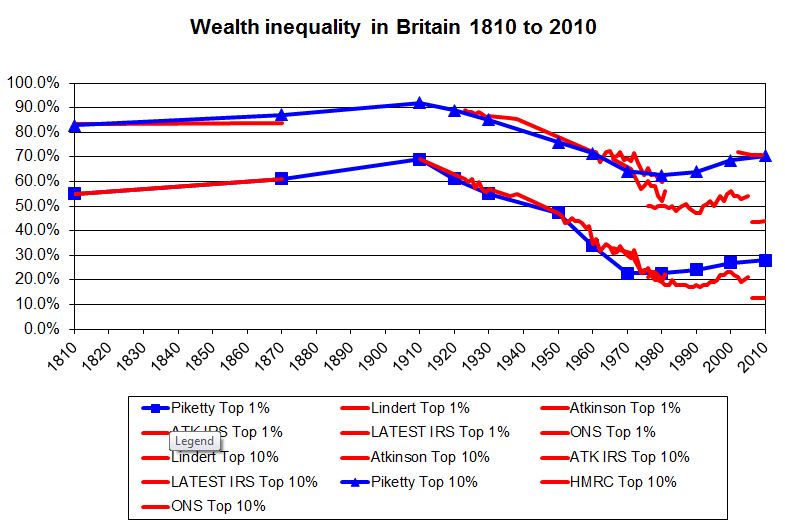
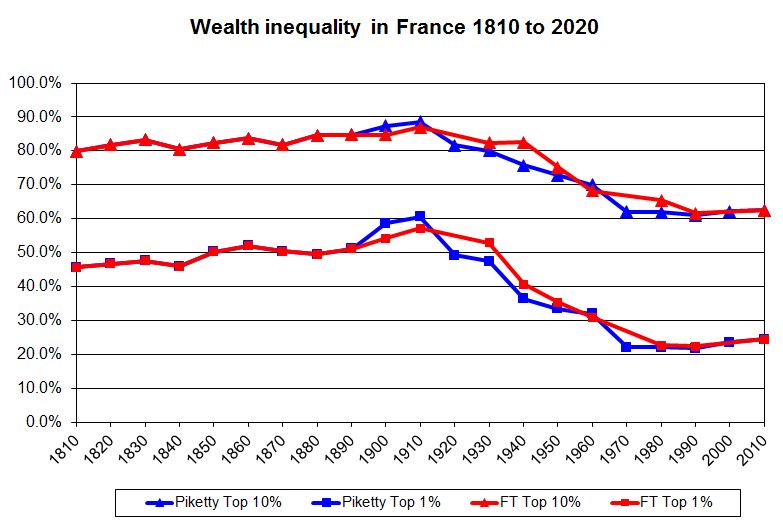
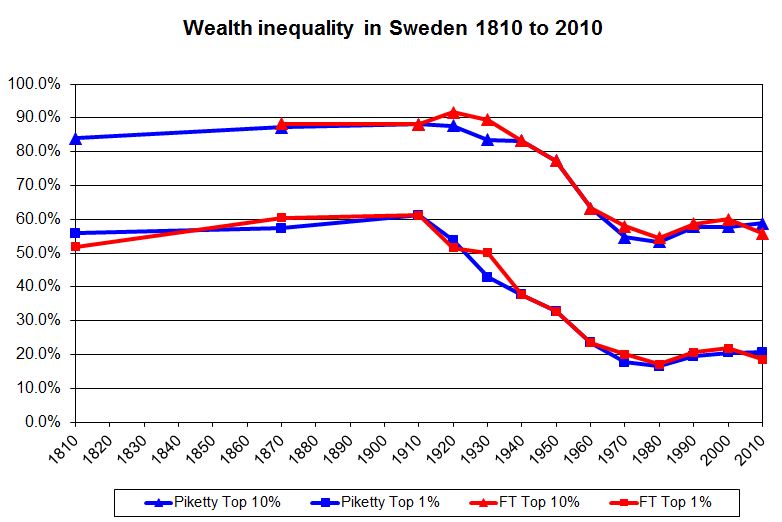
The central theme of Prof Piketty’s work is that wealth inequalities are heading back up to levels last seen before the first world war. The investigation undercuts this claim, indicating there is little evidence in Prof Piketty’s original sources to bear out the thesis that an increasing share of total wealth is held by the richest few.
Prof Piketty, 43, provides detailed sourcing for his estimates of wealth inequality in Europe and the US over the past 200 years. In his spreadsheets, however, there are transcription errors from the original sources and incorrect formulas. It also appears that some of the data are cherry-picked or constructed without an original source.
For example, once the FT cleaned up and simplified the data, the European numbers do not show any tendency towards rising wealth inequality after 1970. An independent specialist in measuring inequality shared the FT’s concerns.
Piketty response to FT data concerns – Thomas Piketty, Financial Times
Let me first say that the reason why I put all excel files on line, including all the detailed excel formulas about data constructions and adjustments, is precisely because I want to promote an open and transparent debate about these important and sensitive measurement issues (if there was anything to hide, any “fat finger problem”, why would I put everything on line?).
Let me also say that I certainly agree that available data sources on wealth are much less systematic than for income. In fact, one of the main reasons why I am in favor of wealth taxation and automatic exchange of bank information is that this would be a way to develop more financial transparency and more reliable sources of information on wealth dynamics (even if the tax was charged at very low rates, which you might agree with).
…
For instance, my US series have already been extended and improved by an important new research paper by Emmanuel Saez (Berkeley) and Gabriel Zucman (LSE). This work was done after my book was written, so unfortunately I could not use it for my book. Saez and Zucman use much more systematic data than I used in my book, especially for the recent period. Also their series are constructed using a completely different data source and methodology (namely, the capitalisation method using capital income flows and income statements by asset class). The main results are available here: http://gabriel-zucman.eu/files/SaezZucman2014Slides.pdf.
…
Of course, as I make clear in my book, wealth rankings published by magazines are far from being a perfectly reliable data source. But for the time being, this is what we have, and what we have suggests that the concentration of wealth at the top is rising pretty much everywhere. Of course, if the FT produces statistics and wealth rankings showing the opposite, I would be very interested to see these statistics, and I would be happy to change my conclusion! Please keep me posted.
A New Critique of Piketty Has Its Own Shortcomings – Justin Wolfers, New York Times
I’m not (yet) convinced by these charges. Before digging in, let’s give credit where it is due: The Financial Times has done a superb job in digging deeply into Mr. Piketty’s data. And Mr. Piketty deserves enormous credit for having attempted the very hard task of extracting meaning from a disjointed and piecemeal historical record of the evolution through time of the distribution of wealth.
I drew the following five conclusions from The Financial Times’s re-analysis:
Not all differences are errors. Some of the issues that The F.T. highlights are quite straightforward, such as where Mr. Piketty appears to have typed in data from the wrong row of a table. But many other issues are less questions about the validity of the data than they are about incomplete referencing. And yet others appear to be judgment calls, albeit made with insufficient documentation.
They essentially agree. While it’s quite natural for a journalist to emphasize the differences between his findings and those of a famous author, the most striking fact is how closely The F.T.’s analysis agrees with Mr. Piketty’s. Their preferred time series for the evolution of wealth inequality in the United States, Britain, France and Sweden are remarkably similar.
Not all differences are equally important. To the extent that The F.T. and Mr. Piketty disagree — and as I say, I think these instances are relatively minor — it’s not yet clear whether the cause is obvious errors as pointed out by the newspaper, or judgment calls where perhaps the professional economist deserves the benefit of the doubt.
The F.T.’s bottom line is muddier than it looks. Mr. Piketty’s broader project is about bringing together disparate sources of data on wealth inequality to try to figure out what has happened through time. This involves seeking ways of comparing otherwise not-very-comparable sources of information, which is a tough job, requiring substantial domain-specific expertise and judgment. The F.T. does a nice job in raising specific concerns with specific data points. But in trying to put together its own series, the paper is at least as guilty as Mr. Piketty of making some pretty big assumptions about the comparability of quite different data sets.
This is a debate about wealth inequality, not income inequality. Mr. Piketty is famous for having produced estimates of not just the share of wealth held by the top 1 percent (or top 10 percent), but also for his estimates showing a greater concentration of income among high earners. The F.T. re-analysis is entirely about wealth inequality, and no serious questions have been raised about the veracity of the data on the rising income shares of the top 1 percent.
Is Piketty all wrong? – Paul Krugman, New York Times
I don’t know the European evidence too well, but the notion of stable wealth concentration in the United States is at odds with many sources of evidence. Take, for example, the landmark CBO study on the distribution of income; it shows the distribution of income by type, and capital income has become much more concentrated over time:
It’s just not plausible that this increase in the concentration of income from capital doesn’t reflect a more or less comparable increase in the concentration of capital itself.
Beyond that, we have, as Piketty stresses, evidence from Forbes-type surveys, which show soaring wealth at the very top. And we have other estimates of wealth concentration, like Saez-Zucman, that use completely different methods but point to the same conclusion.
And there’s also the economic story. In the United States, income inequality has soared since 1980 by any measure you use. Unless the affluent starting saving less than the working class, this rise in income disparity must have led to a rise in wealth disparity over time.
The point is that Giles is proving too much; if his attempted reworking of Piketty leads to the conclusion that nothing has happened to wealth inequality, what that really shows is that he’s doing something wrong.


{kind=link}
{kind=link}
{kind=link}
{kind=link}